Webpack 作为一个构建工具,它面向开发者的接口包括了构建配置或插件开发,而内部构建过程的实现相对比较「黑盒」,加上它代码量非常大,涉及的概念比较多,对新手而言,理解它的「内部实现」并没有那么容易,比如说它的构建过程都发生了什么,为什么说它是一个可扩展的架构设计?
本文引用一个示例工程,介绍 Webpack 整体的构建流程,但对于一些独立的模块实现,比如 Loader、Plugin 或 Tree-Shaking 优化这些,本文不会深入研究,后续的系列文章再单独介绍。
以下是一个基于 ESM 模块规范编写的示例工程的项目结构,Webpack 的版本是 5.64.4,示例代码已托管到Github:
1 | ├── esm |
Webpack 配置和模块依赖关系如下:

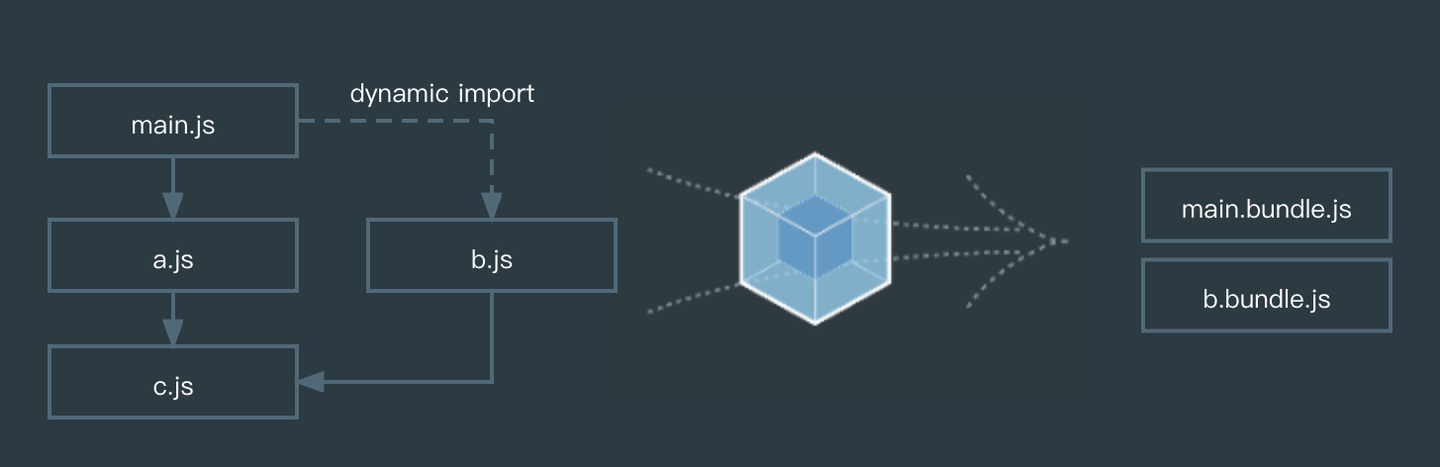
在进入流程之前,简单地介绍一下 Webpack 中一些术语(Glossary):
- Entry Points:构建流程的入口,它决定了 Webpack 从哪里模块开始构建。
- Compiler:Webpack 的编译器,通常情况一个构建流程中只有一个 Compiler,直至退出构建程序。
- Compilation:也是 Webpack 的编译器,但它是每次编译都会实例化一次新的 Compilation,比如 watch 模式下会有多次编译的情况。
- Hooks:Webpack 的一些任务需要「外包」出去,Hooks 是通知或接收消息的通道,核心实现是Tapable库,下文把 Hooks 统称为「钩子」。
- Module:在 Webpack 中,Javascript 代码或图片视频等静态资源都算模块。
- Chunk:比 Module 粒度更大的「块」,可以组合成 Bundle,有两种形式的 Chunk,一种是 Entry Points 对应的 Chunk,另外一种是 Dynamic Imports 或 Code-Splitting 产生的 Chunk。
- Bundle:源代码文件在经过加载和编译处理和优化之后的最终产物。
Webpack 的构建流程非常长,它就像一条生产的流水线,从CLI读取「产品订单配置」(webpack.config.js),到「生产部」(Compiler),然后交给具体的「车间」(Compilation)执行,最后「打包」(Seal)成产品(Assets)。
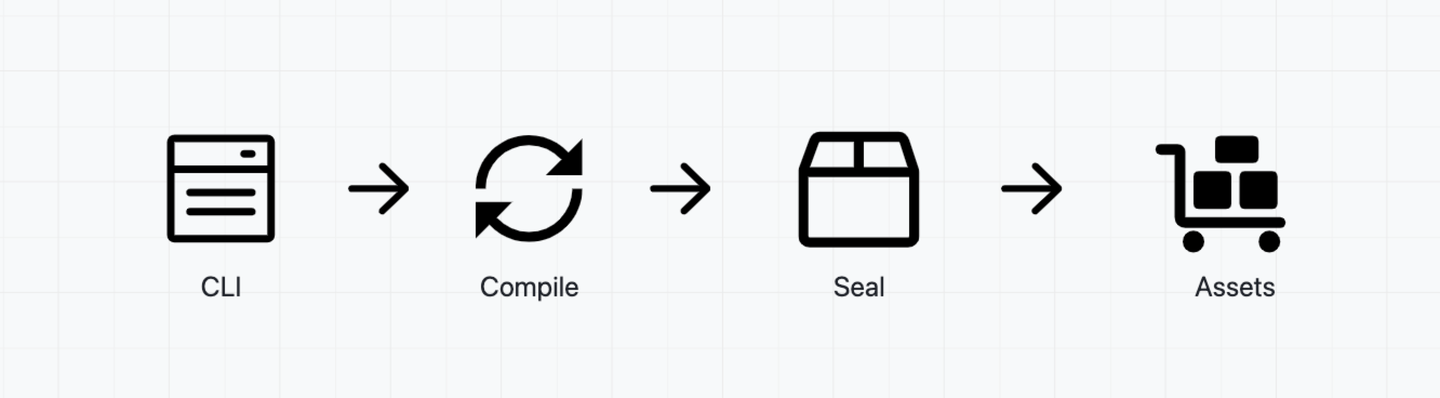
本文把 Webpack 的构建流程分成四个环节,即CLI 初始化、编译模块、打包模块和产物输出。
一、CLI 初始化阶段
几乎所有构建工具都会提供 CLI 来帮助开发者快速地执行构建任务,而 Webpack 则是把相关构建指令实现拆分了出去,交给另外单独的 npm 模块,它就是webpack-cli ,CLI 与构建实现(webpack-core)解耦带来的好处是,可以满足一些第三方工具的构建需求,比如 next.js 等,你可以理解为 CLI 是底层构建的快捷指令。

CLI 的指令会携带 process.argv 参数进来,这些参数可以覆盖 Webpack 的默认配置,优先级比自定义或默认配置高,读取到参数后,会校验参数的合法性以及自动根据参数配置使用对应的 Plugin,最终会调用 webpack 方法,创建一个 Compiler,而 Compiler 的代码实现是在 Webpack/lib/webpack.js 文件(在线代码戳这里:📌)。

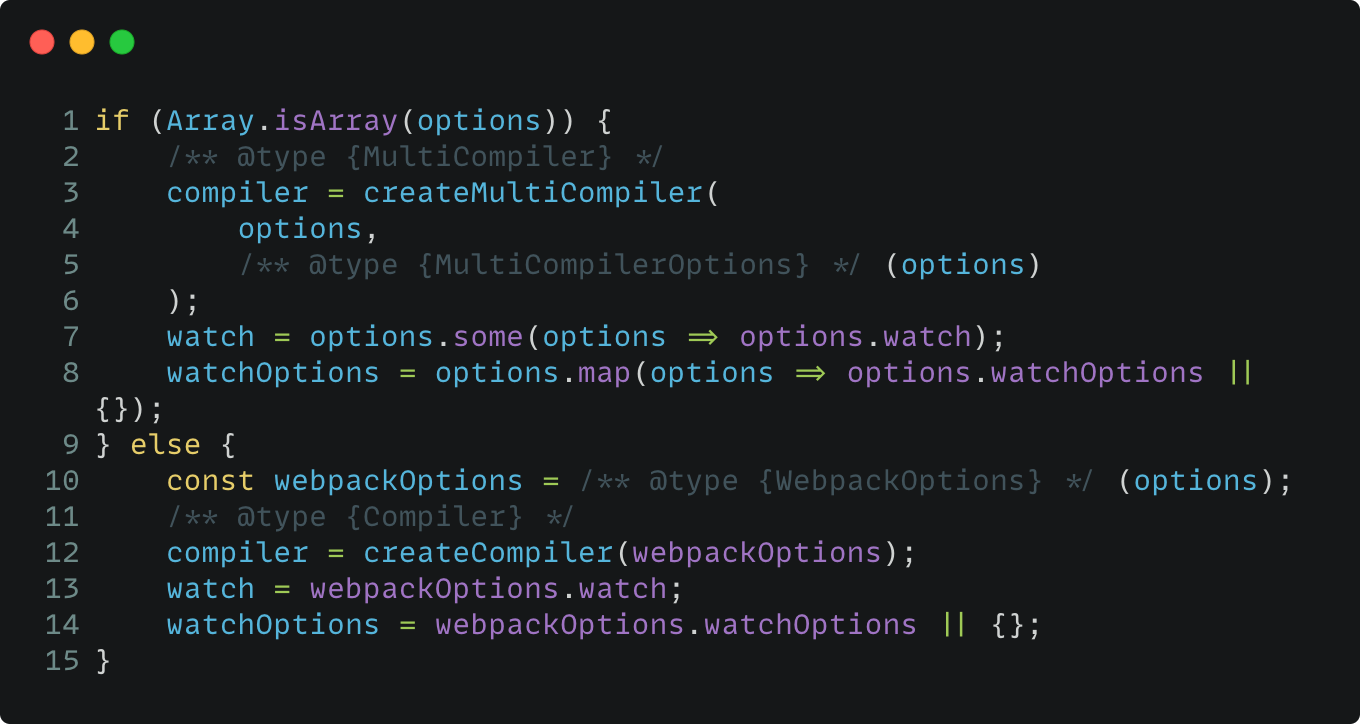
其中的 options 是指自定义配置和已经过 CLI 处理之后的配置信息,Webpack 会根据配置信息,来确定需要创建的 Compiler 类型:
- Compiler:配置信息不是 Array 类型时,默认为单 Compiler 模式。
- MultiCompiler:配置信息是 Array 类型时,默认为多 Compiler 模式,可用于独立构建不同配置的产物下的场景,但目前它还不支持多个 Compiler 的并行构建,感兴趣可以继续到官网了解(在线文档戳这里:📌 )。
创建 Compiler 时,Webpack 还处理了一些默认配置,比如会自动地添加「最佳实践」的构建参数和插件,从而让业务工程减少繁杂的配置项也能达到满意的构建性能,这里就不做过多的介绍,对默认添加的配置感兴趣的可以到 github 仓库查看代码(在线代码戳这里 📌)。

创建完 Compiler 后,Webpack 还需确定当前的构建是 watch 还是 run 模式 ,前者是监听文件更新后会重新触发构建,后者会在构建完成后就会退出进程,本文主要介绍 run 模式的构建流程。
至此,我们完成了 Webpack 的第一阶段任务,通过 CLI 的初始化和创建 Compiler ,以及确定构建的配置信息。有了这些配置,我们就可以进入编译阶段,下个阶段主要是介绍 Webpack 如何处理模块及怎么样生成模块依赖图。
二、编译阶段
经过 CLI 初始化和创建 Compiler 之后,我们需要把视角移到 Compiler 和 Compilation 这两个构造函数上来,上文已经提到了,他们是整个 Webpack 构建的核心,而编译阶段是从解析 Entry Points 开始,直至构建完整的模块依赖图(Module Graph),因此该阶段可以分为两个部分来讲。
1.解析 Entry Points
Entry Points 是定义模块依赖图的起始点,它具有多种形态,比如 Single Entry,Multiple Entry,但本文只对 Single Entry 进行流程分析。
接上个阶段的run方法,它是 Compiler 模块的一个方法,在webpack/lib/Compiler.js 文件,继续分析流程:
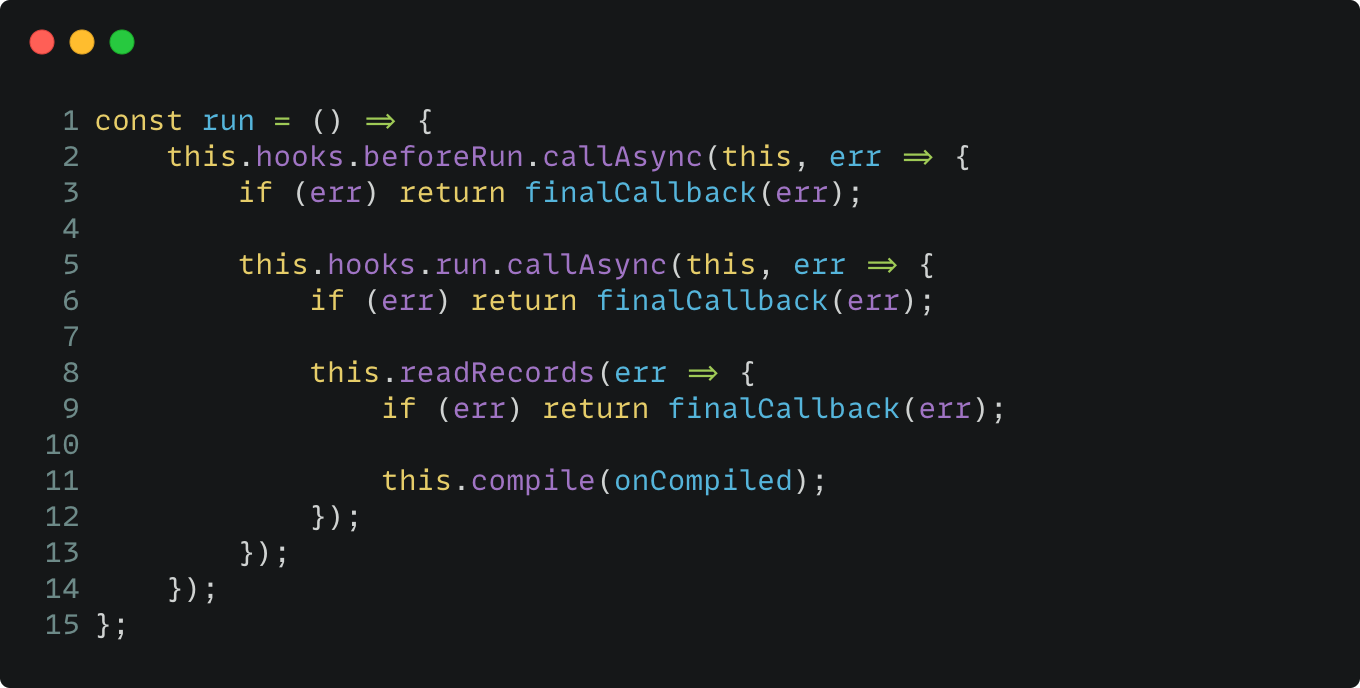
run 函数里面调用了多个钩子,分别是 beforeRun、run 和 records (records 跟优化 Bundle 相关,感兴趣可以戳这里 📌)相关钩子,这些都是构建的前置钩子,因此如果你需要为构建前执行一些任务,可以考虑这些钩子。
最终,在回调的最里面,执行了 this.compile(onCompiled),这里才是编译的入口,可以看出 Webpack 的前期铺垫比较长,而 compile 的实现如下:
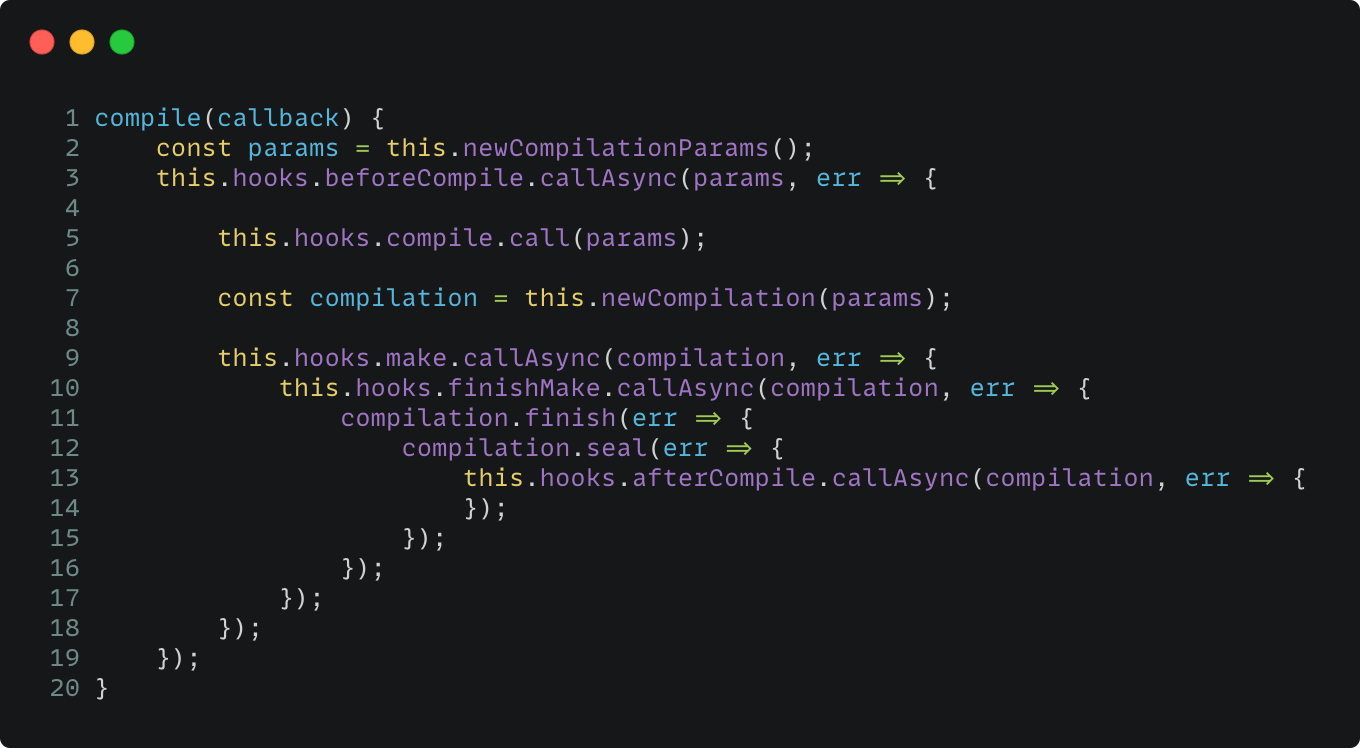
都是一些 Callback 函数,为了方便阅读,删除了一些无关的代码,但这里已经包括 Webpack 构建流程后续的所有阶段,简单梳理一下:
1.首先,newCompilationParams 是获取 Compilation 的参数,主要是创建了两个 Factory 函数:
NormalModuleFactory 处理普通的依赖,使其转为 NormalModule,在构建 Module Graph 时将使用到。
ContextModuleFactory 处理 require.context 这种特殊的模块解析,将解析出来的依赖继续传递给 NormalModuleFactory 来处理。
2.将 params 参数传给构造函数 Compilation,然后进行实例化,同时触发 compilation 这个钩子事件。
3.调用 make 钩子,不过 Compilation 并没有直接监听这个钩子来触发构建,在检索源代码后,发现共有 7 处 tap(监听)该事件 ,比如有 EntryPlugin 和 DynamicEntryPlugin,这两个 Plugin 处理不同类型的 EntryPoint,所以 Webpack 的设计思路,在必要时会把某项「处理任务」封装成 Plugin,来提高构建流程的灵活性。
4.finishMake、finish、seal 这些都是构建完 Module Graph 之后的钩子事件,这里先忽略。
上面提到的 EntryPlugin 就是来解析 Entry Point,值得一提的是,一个 Entry Plugin 只处理一个 Entry Point,它主要的任务是将 Entry Point 转为 EntryDependency,然后再交给 Compilation 进行编译:
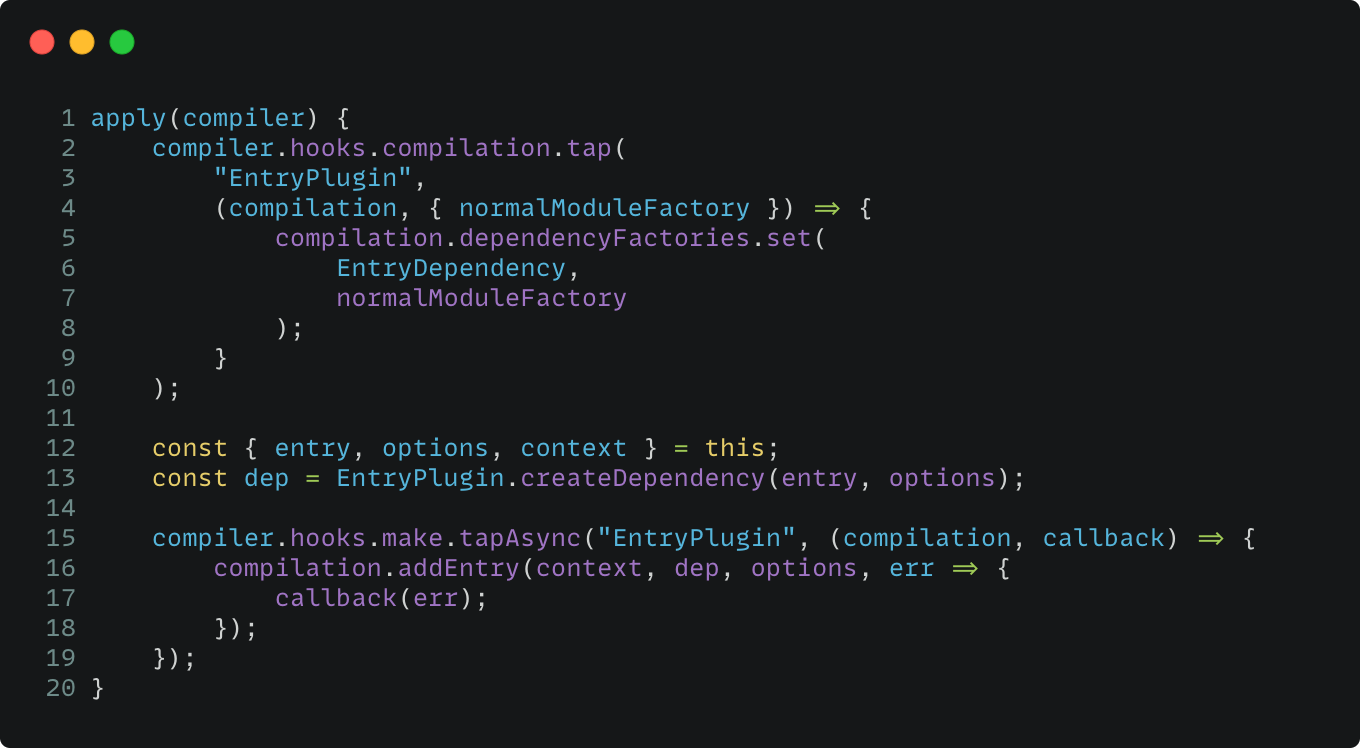
通过 compilation 钩子事件,为 EntryDependency 设置处理模块和依赖的函数:NormalModuleFactory ,并且将 Entry Point 实例化为 dep,此时,如何 Compiler 发来了「make」事件后,EntryPlugin 就会将 dep 传入到 Compilation addEntry 这个方法,从而正式进入构建 Module Graph 阶段。
2.构建 Module Graph
Module Graph 是 Webpack 中很重要的概念,你也可以理解为 Module Tree,它描述了模块之间的依赖关系。
这部分主要讲如何构建 Module Graph,接上一阶段的 addEntry 方法,中间有一些过程代码被省略掉,最终流转到 addModuleTree 这个函数:
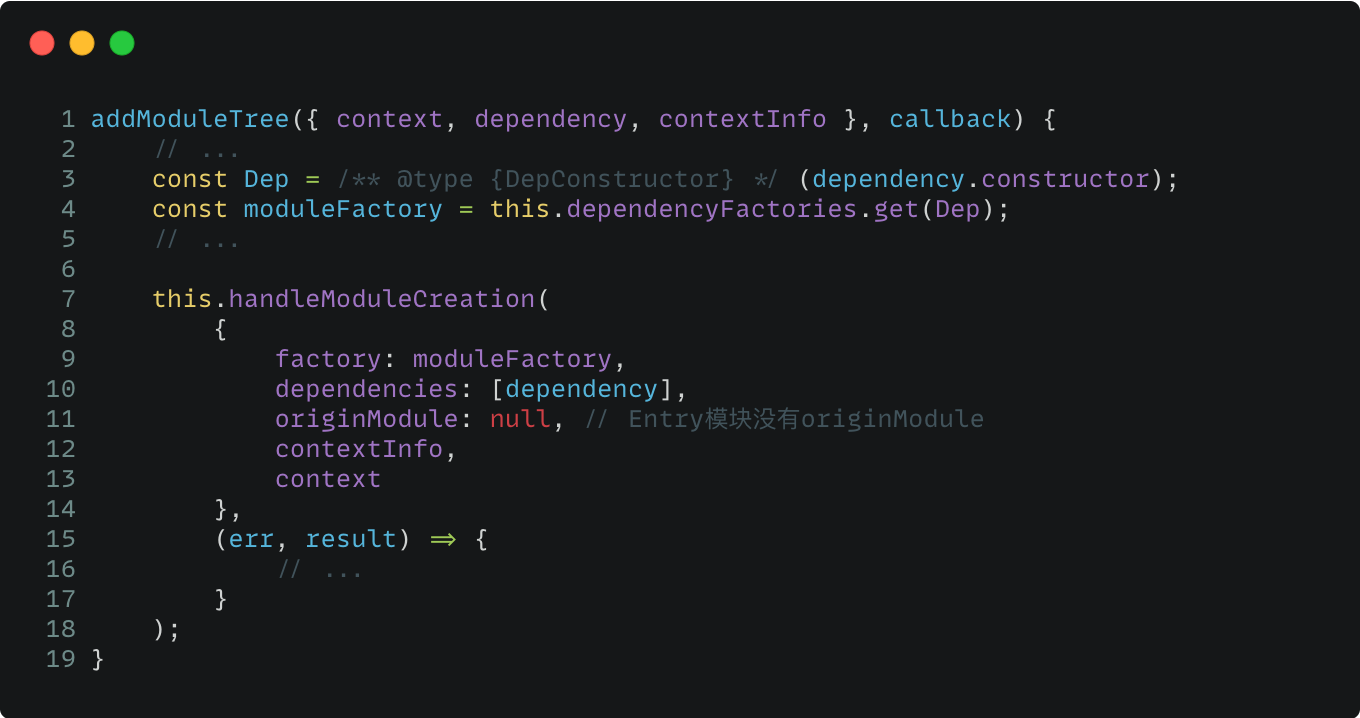
这个函数很重要,它通过传入依赖参数:dependency,就能够根据当前的依赖进行构建,比如 PrefetchPlugin 这个插件也是通过这个函数,来动态添加 dependency,从而完成模块的预编译。addModuleTree 的主要流程是:
- 获取处理当前模块的 Factory 函数,在我们的构建流程用到的是 NormalModuleFactory 。
- handleModuleCreation 函数传入 factory 和 dependencies 并执行调用,后续的递归解析模块时也会回到这个函数。
继续流转到 handleModuleCreation 函数:
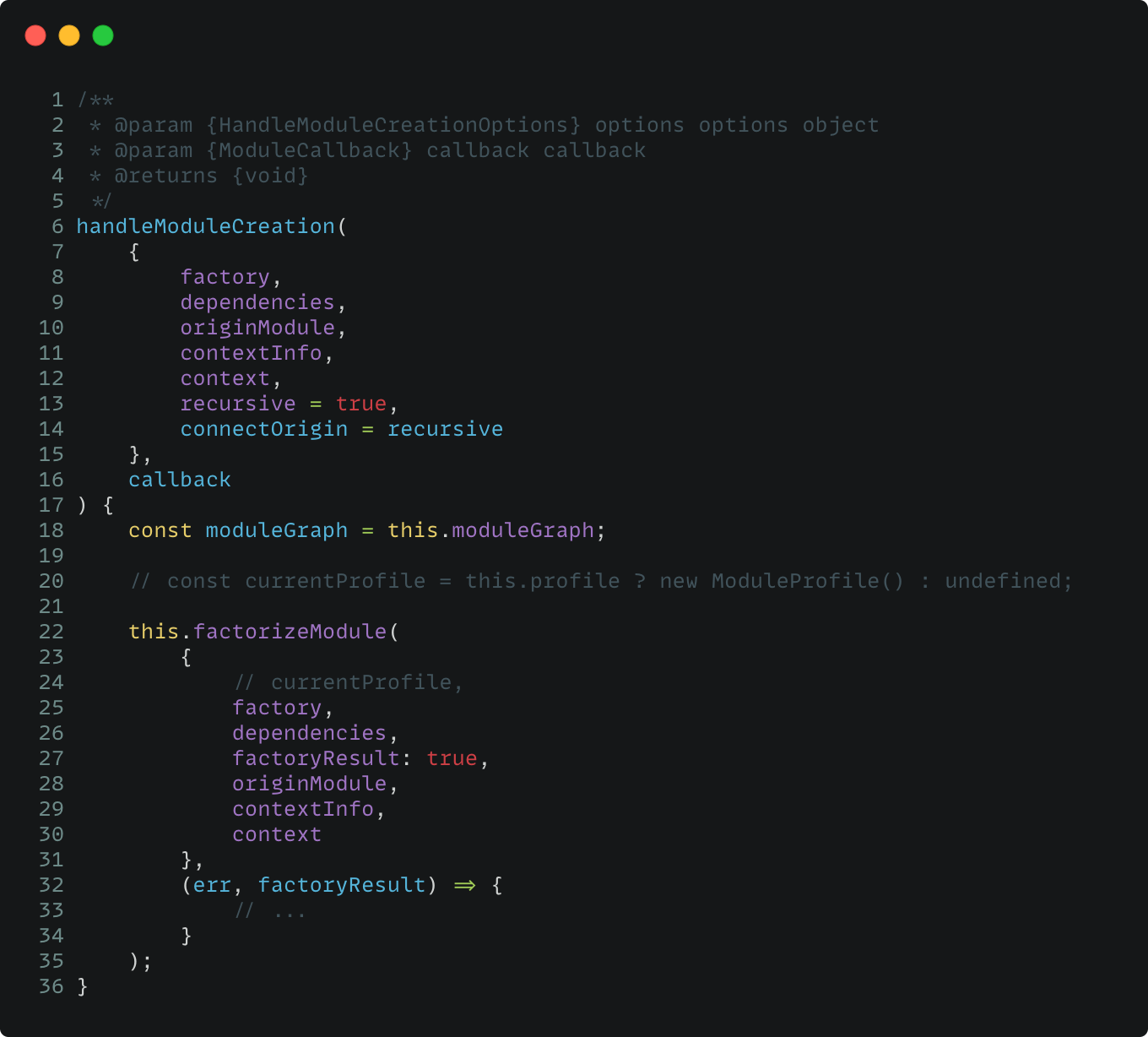
函数里面先调用 factorizeModule 函数,从函数名能猜出是「转换为 Module」的意思,这个函数传入 factory、dependecies 等参数,最终是流转到 NormalModuleFactory 的 create 方法来完成模块的构建。NormalModuleFactory 的处理流程比较长,但目的比较明确,就是给它传入依赖:dependencies,它会将依赖逐个转为 NormalModule 。
NormalModuleFactory 本身是继承于 Tapable,因此它的实例上具有模块构建相关生命周期的钩子,因此在需要对模块信息进行修改时,可以利用这些钩子来编写插件。
值得一提的是,在 NormalModuleFactory 在处理模块解析过程中,需要对模块文件进行寻址,在 Webpack 中,它没有直接使用 NodeJS 的 require.resolve,而是交给了另外一个独立库:enhanced-resolve来完成,这个库在实现解析文件时,也用到了 Tapable 这个依赖,因此它在解析过程中会触发相关生命周期的钩子,下面用一张图来描绘 NormalModuleFactory 的整个流程。
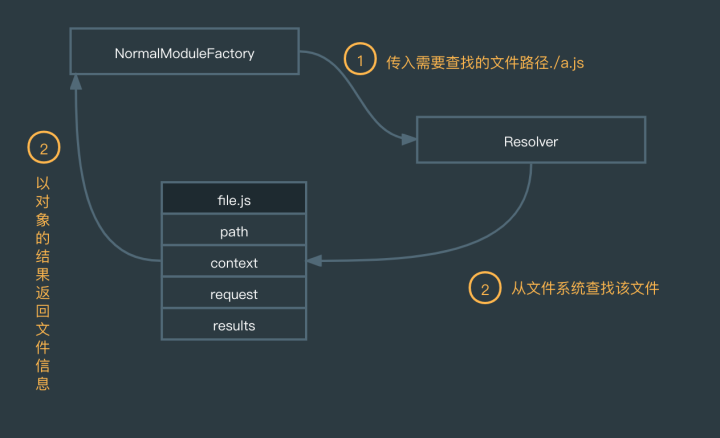
总结一下,factorizeModule 函数的作用是将依赖转换为能够描述当前模块的信息对象,这种模块信息对象在 Webpack 中叫 NormalModule,它的数据结构如下:
1 | NormalModule { |
此时,EntryDependency 已经转换为 NormalModule,我们称之为 EntryModule,接下来是将 EntryModule 添加到 Module Graph,省略掉非关键代码之后:
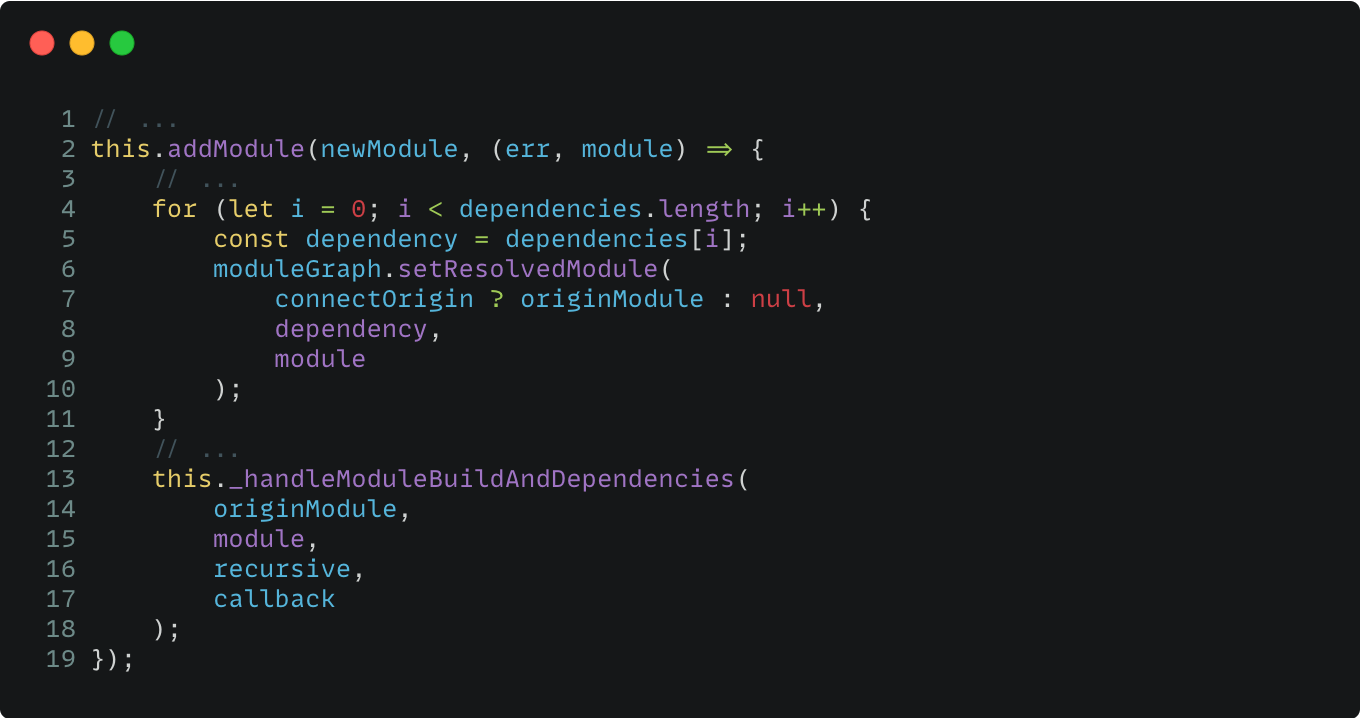
先对 dependencies 进行遍历然后得到单个的 dependency,比如当前的 dependency 是[EntryDependency],然后调用 moduleGraph.setResolvedModule 函数,此时传入了三个参数:
- originModule 指向父级模块,对于 EntryDependency 来说,它没有父级模块,所以指向 null。
- dependency 指模块的依赖,包括 EntryDependency、HarmonyImportSideEffectDependency、HarmonyImportSpecifierDependency 等。
- module 指模块,包括 NormalModule、ContextModule 等。
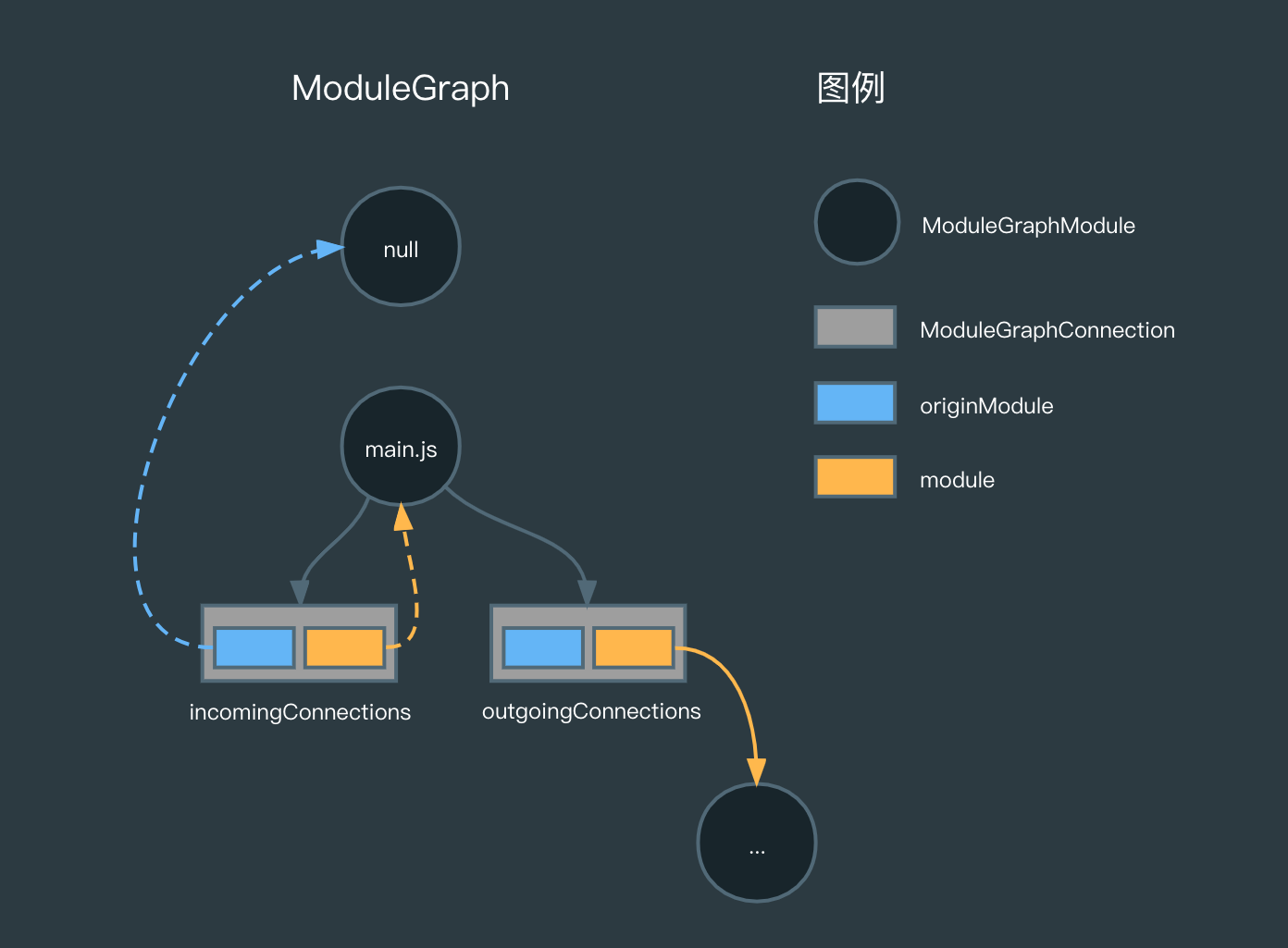
因此当前的 Module Graph 可以用一张图来描绘,其中 ModuleGraphModule 是 Graph 的节点,每个节点下保存着 incomingConnections 和 outgoingConnections 属性,前者是用于指向父节点,后者是用于指向子节点:
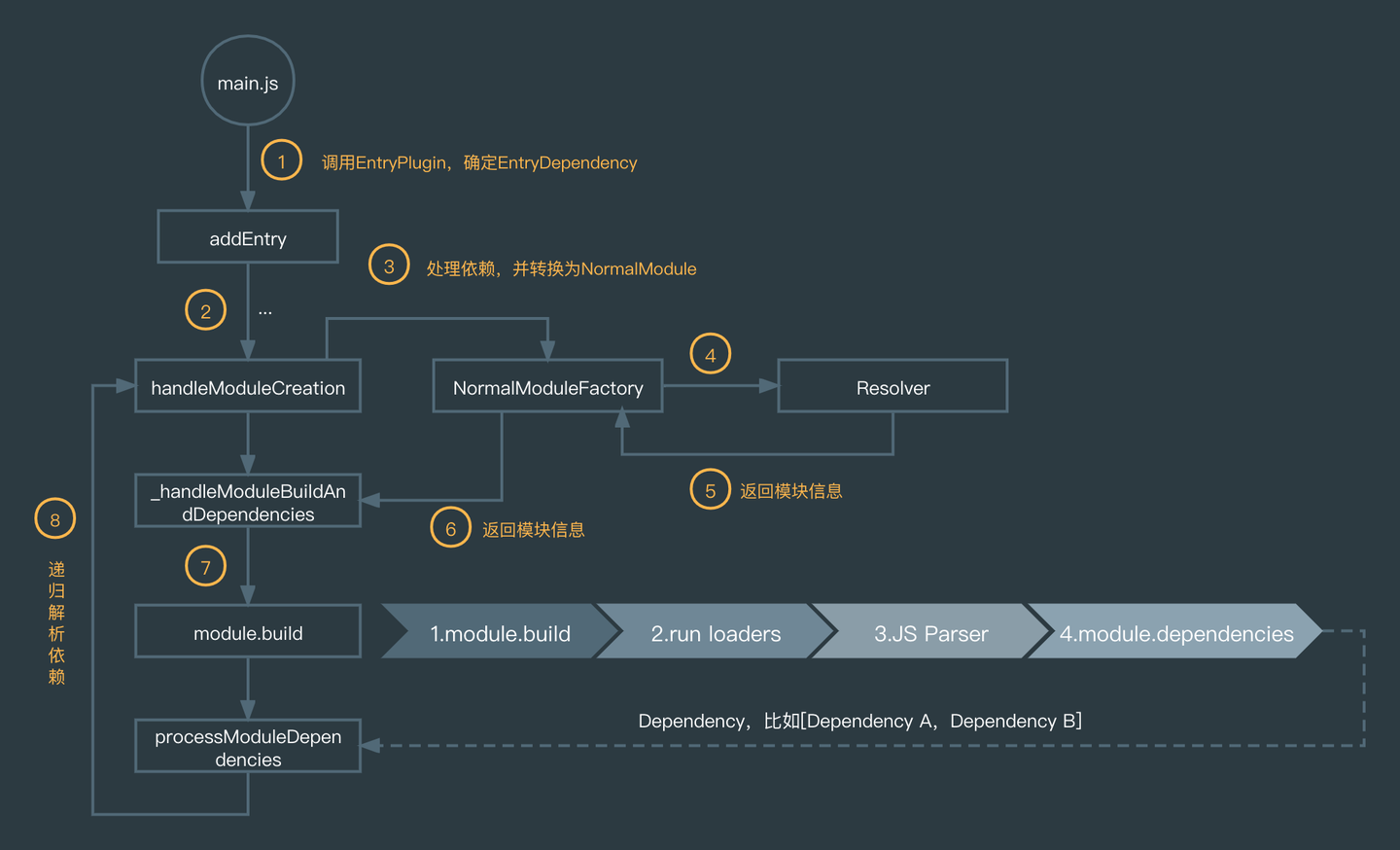
处理完 EntryModule 之后,它具有自己的子依赖,因此需要调用_handleModuleBuildAndDependencies 来处理子依赖,这个过程又调用了很多中间函数,最终是走到 module.build,相当于 EntryModule.build。
这里会涉及到一个我们较为熟悉的概念,它就是 loader,loader 本身是相对比较独立的模块,它是 Webpack 构建流程中的一个分支,这里不打算深入研究它的内部实现,简单画个图来描述从 module.build 到解析出模块依赖的中间过程:

- 调用 NormalModule.build;
- 解析并执行相关的 loader;
- 使用acorn解析当前模块,得到 AST 后,可以分析出模块依赖;
- 得到模块依赖。
解析完当前的模块依赖后,构建流程会重新回到 handleModuleCreation,并把这些依赖转为 NormalModule,一直递归下去,直到该模块没有依赖为止,就当前的示例工程来讲,最终会得到这样的 ModuleGraph:
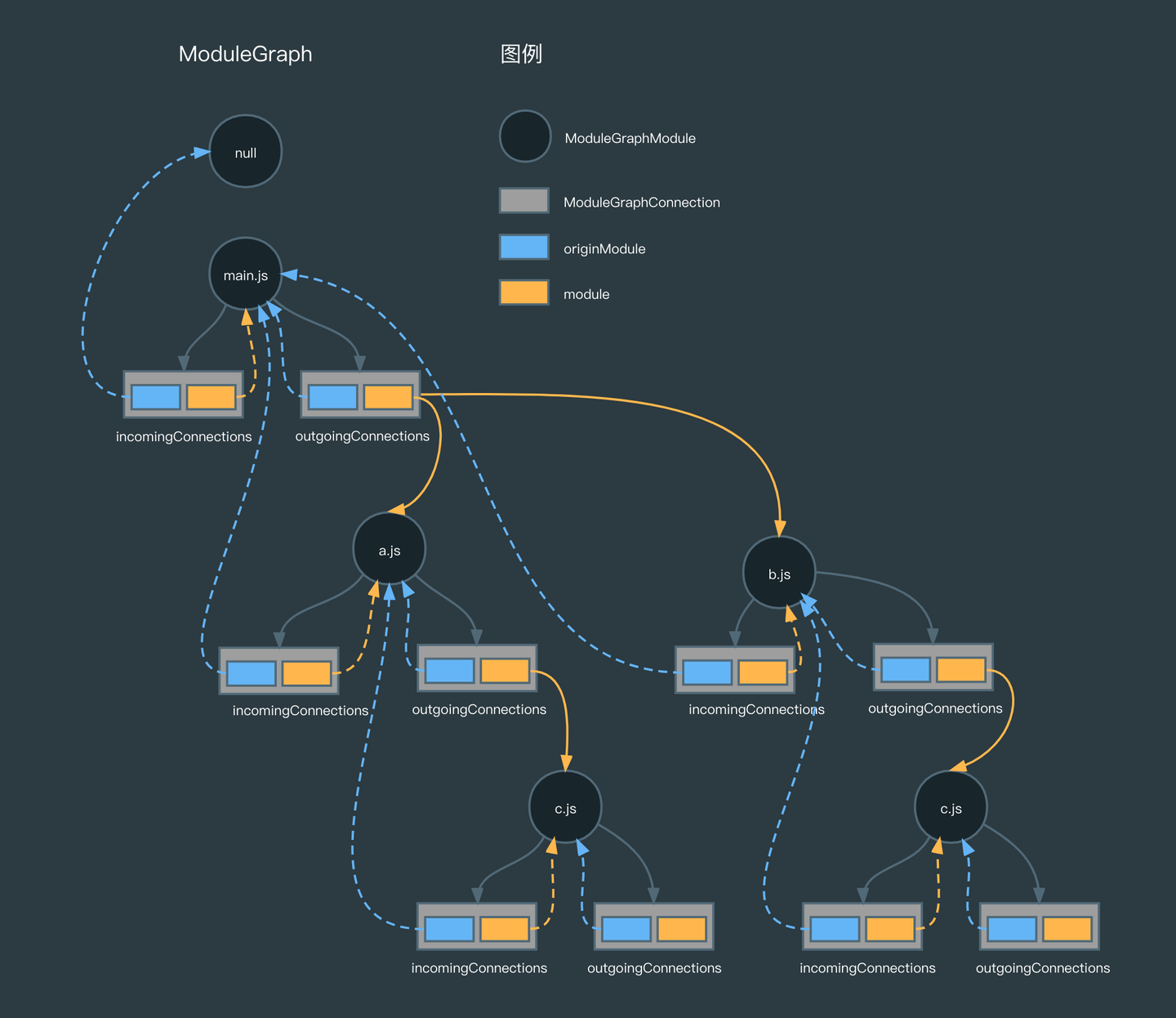
在生成 Module Graph 之后,就标志着该阶段已经完成,接下来是进入打包阶段,最后用一张图来帮助总结该阶段的整体流程:
三、Seal 阶段
上个阶段结束后,我们已经得到 Module Graph,但这些模块需要重新组装成 Bundle 或生成静态资源后,才能被浏览器所加载,因此本阶段将介绍如何组装模块这个过程。
1. 构建 Chunk Graph
seal 的中文意思是表示「密封」,类似产品需要进行分类打包的意思,但它不仅仅是把 module 合并成 chunk,比如在上个阶段,我们只是分析出模块之间的依赖关系,而模块转为目标代码也是在这个阶段完成的。
先从 seal 函数入口开始分析,它在webpack/lib/Compilation.js这个文件:
如果说编译阶段的 Module Graph 是模块之间依赖关系的描述,那么 seal 阶段的 Chunk Graph 则是 ChunkGroup 关系的描述,Chunk Graph 的数据结构如下:
1 | ChunkGraph{ |
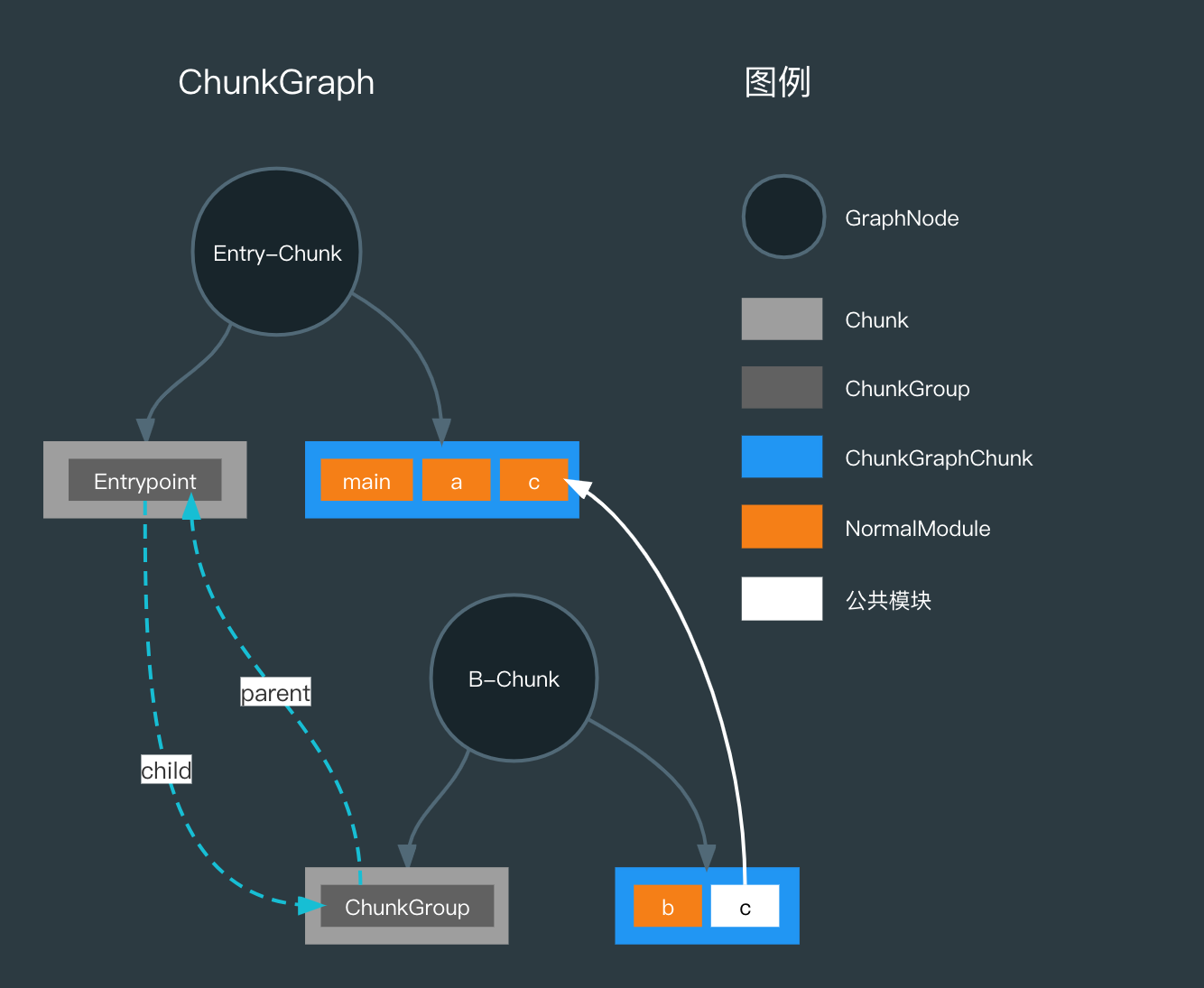
这里需要先明确三个概念:ChunkGraph、_chunks、ChunkGraphChunk、ChunkGroup 和 Chunk:
- ChunkGraph 是 ChunkGroup 之间的依赖关系描述。
- ChunkGroup 是 Chunk 的集合,在 Webpack 中,EntryPoint 也是 ChunkGroup 中的一种。
- ChunkGraphChunk 是 ChunkGraph 节点。
- _chunks 是 ChunkGraphChunk 的 WeakMap,数据结构是 WeakMap<Chunk, ChunkGraphChunk>。
- Chunk 是 Module 的集合。
通常情况下,一个 Entry Point 只会对应一个 ChunkGroup,但在我们的示例工程中由于 Dynamic Imports,因此 Webpack 会额外创建另外一个 ChunkGroup,而且从依赖关系上,它属于 EntryPoint 的 Child,这就是需要 Webpack 构造 Chunk Graph 的原因,多个 ChunkGroup 可能存在依赖关系。
我们继续分析 seal 的流程,这里调用一个非常关键的钩子 optimizeDependencies ,Webpack 就是从这里对模块进行 Tree-Shaking 的优化,Tree-shaking 这部分在之后的系列用单独一篇文章来介绍,现在忽略它不影响我们分析接下来的流程。
接着是遍历 Entry Points(可能有多个 Entry Point),然后构造出一个 Key 为 Entrypoint,Value 是 NormalModule 的集合:chunkGraphInit<Entrypoint, NormalModule[]>,就当前示例工程构成出来的 Map 就是:
1 | chunkGraphInit { |
这个 Map 传入到另外一个函数:buildChunkGraph 中 ,这个函数对 chunkGraphInit 进行处理,主要有两部分的工作:
- visitModules:从 EntryModule 开始遍历,并结合 Module Graph ,递归访问每个模块,有关联关系的 Module 会合并到一个 chunkGroup,而 Dynamic imports 会另外创建一个 chunkGroup。整个流程有两个队列:queue 和 queueDelayed,前者存放 Sync Block(同步的模块),后者存放 Async Block(异步的模块),执行顺序上是先处理完成同步模块,再处理异步模块。
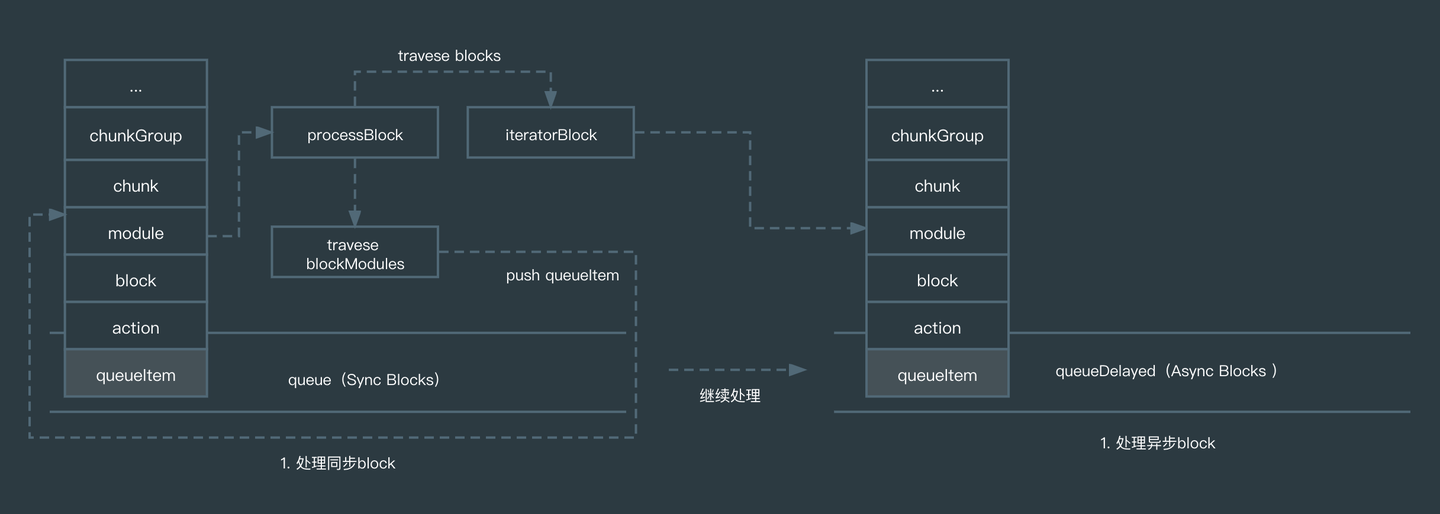
- connectChunkGroups:关联 ChunkGroup 之间的关系,使得它们具有父子关系依赖,比如动态导入的 ChunkGroup 是 Entrypoint 的 Child。
对于当前的示例工程来讲,最终会得到这样的 Chunk Graph:
Chunk Graph 构建完成后,后续还会调用一些优化 Chunk 的钩子事件,对 Chunk 进行优化之类的 Plugin,比如:
- SplitChunksPlugin 使用 optimizeChunks 钩子将 Chunk 进行分包。
- ModuleConcatenationPlugin 使用 optimizeChunkModules 来实现作用域提升(scope hoisting),减少 runtime 的代码量和提升性能。
这个阶段的目标是构建 Chunk Graph 和确定 Chunk Group,下一阶段 Webpack 就会对这些 Chunk Group 进行处理,转化为 Assets。
2.生成 Asssets
上文提到,在构建 Module Graph 时,只是得到模块之间依赖关系,并没有生成目标产物,所以接下来将分析 Module 是如何生成 Asset 的。大概可以分为两步,先对模块进行处理,生成 Webpack Source,再使用 RuntimeTemplate 及 sourceAndMap 方法生成对应的 Runtime 代码,关键代码是:
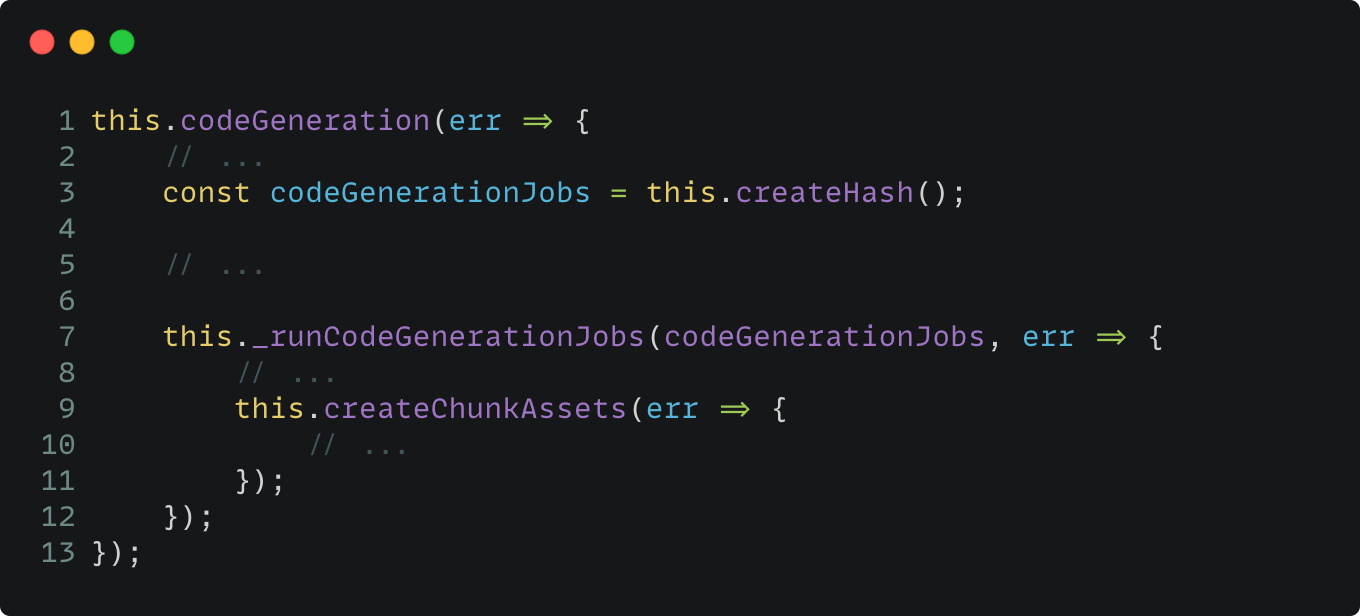
分析代码:
- codeGeneration 是对已有的模块依赖图进行遍历,得到的每个模块都算一个 job,然后传入给_runCodeGenerationJobs 进行处理,逐个地将模块转为能够描述源代码、sourcemap 等信息的对象,它就是 Webpack Source。
- createHash 会遍历 Chunks,找出当前 Chunk 所需的 RuntimeModule,比如 GlobalRuntimeModule、JsonpChunkLoadingRuntimeModule,并且再次调用_runCodeGenerationJobs,转为 WebpackSource。
- createChunkAssets 主要通过 Template 和 Webbpack Source 对象本身的 sourceAndMap 方法,生成 Runtime 代码,这个过程叫 render。比如对于 Entrypoint 来说,最终 render 的是 ConcatSource:
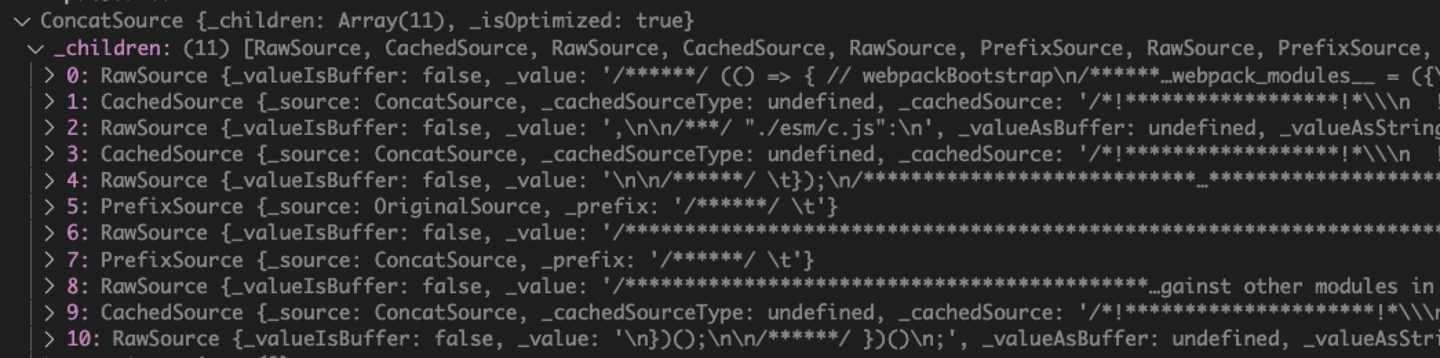
最终我们将得到了多个 asset 对象:
1 | b.bundle.js |
然后,Webpack 会从 seal 函数一直回调到 Compiler 的 onCompiled 方法,并且调用 emitAssets 函数,将 assets 写入到磁盘文件系统(使用 DevServer 时会替换为内存文件系统,以此来提升构建的效率),在写完文件之后,Webpack 会再调用一些 needAdditionalPass,done,additionalPass 这类的后置处理钩子。
得到 Bundle 文件之后,整个构建过程在这里就结束了。
四、总结
本文主要是介绍了 Webpack 的整体构建过程,涉及到的细节比较多,但关键点就几个:初始化 Webpack 的配置参数-构建 Module Graph-构建 Chunk Graph-生成 Runtime 代码-写入到文件系统中。
理解整个过程,不仅有助于我们在遇到构建问题时,能够快速找到对应的节点去 Debug 代码,而且能更好地理解 Webpack 的一些分支流程,例如 Loader、Plugin、Tree-shaking 优化这些比较独立的模块实现。
Webpack 的代码量非常大,本文花了一周的时间源码调试、收集资料和文章撰写,另外参考一些写得非常好的文章,比如:
- 范文杰:[万字总结] 一文吃透 Webpack 核心原理
- An in-depth perspective on webpack’s bundling process - JavaScript inDepth
这些文章对我的帮助很大,同时我结合了自己的理解完成这篇文章,所以细节上如果有表达错误的,欢迎指出,文章可能会不定时更新,同时后续系列会再介绍其它的分支流程,欢迎关注,感谢您的阅读。
[本文谢绝转载,谢谢]